AIبالعربي – متابعات
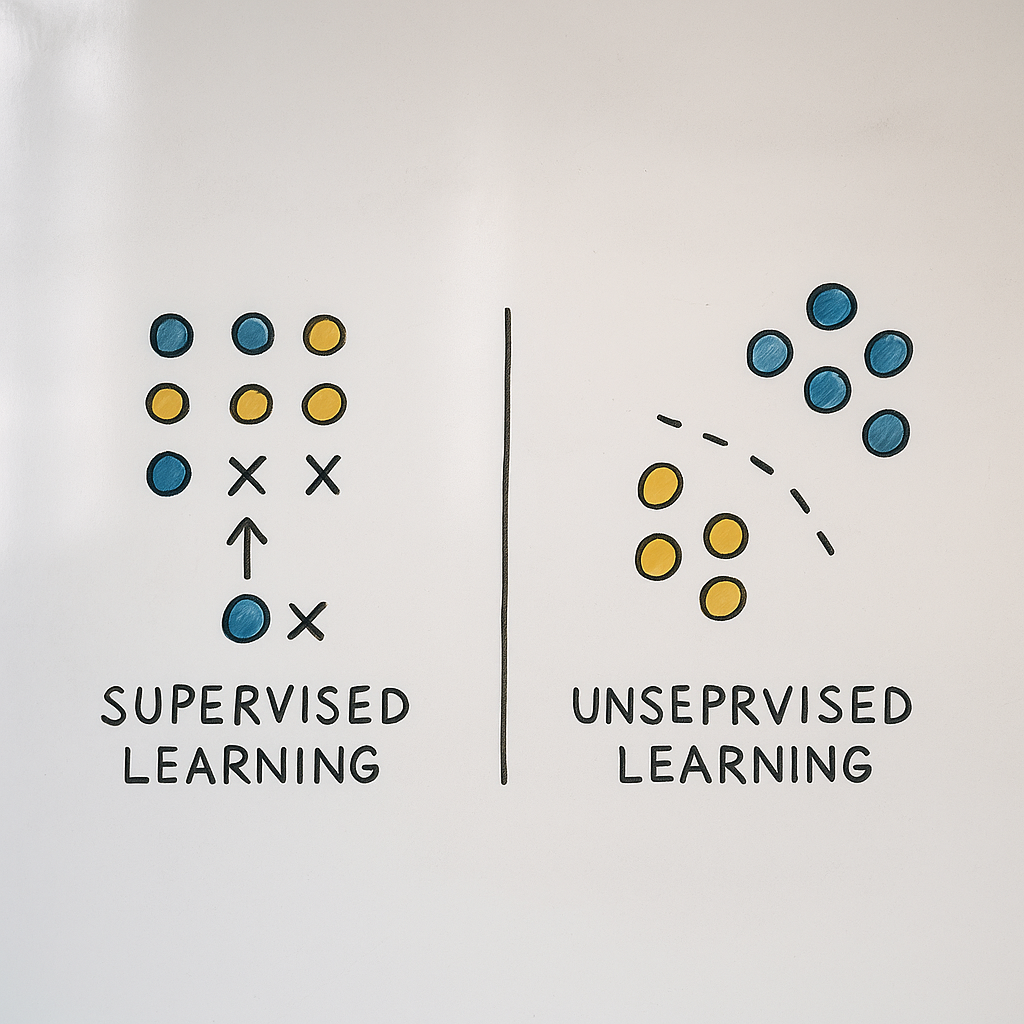
الفرق بين Supervised Learning وUnsupervised Learning أن الأول يعتمد على بيانات مُعلَّمة مسبقًا لتدريب النموذج على التنبؤ، بينما الثاني يتعامل مع بيانات غير مُعلَّمة لاكتشاف الأنماط والعلاقات المخفية.
يُعد هذان النهجان من الأساليب الأساسية في تعلم الآلة، ويختلفان في طريقة التدريب، نوع البيانات، وأهداف الاستخدام.
ما هو Supervised Learning؟
Supervised Learning هو أسلوب في تعلم الآلة يعتمد على تدريب النموذج باستخدام بيانات مُعلَّمة تحتوي على مدخلات ومخرجات معروفة مسبقًا.
يتعلم النموذج العلاقة بين المتغيرات المستقلة والنتيجة الصحيحة بهدف التنبؤ الدقيق عند إدخال بيانات جديدة.
يتضمن هذا النهج نوعين رئيسيين:
– الانحدار (Regression) للتنبؤ بقيم رقمية مستمرة.
– التصنيف (Classification) لتحديد فئات أو تسميات محددة.
يعتمد الأداء على جودة البيانات المُعلَّمة ودقتها.
كيف يعمل Supervised Learning؟
يعمل من خلال تزويد الخوارزمية بأمثلة تدريبية تحتوي على الإجابة الصحيحة ليتمكن النموذج من تقليل الخطأ وتحسين التوقعات تدريجيًا.
تمر العملية بالمراحل التالية:
– إدخال بيانات تدريبية مُعلَّمة.
– اختيار خوارزمية مناسبة.
– حساب الخطأ بين التوقع والنتيجة الفعلية.
– تحديث المعاملات لتقليل الخطأ.
– اختبار النموذج على بيانات جديدة.
كلما زادت دقة الوسوم، تحسنت جودة النموذج.
أمثلة على استخدامات Supervised Learning
يُستخدم في الحالات التي تتوفر فيها بيانات تاريخية واضحة بنتائج معروفة.
من أبرز التطبيقات:
– كشف البريد الإلكتروني العشوائي.
– التنبؤ بأسعار العقارات.
– تشخيص الأمراض من الصور الطبية.
– التعرف على الوجوه.
– تحليل مخاطر الائتمان.
تتميز هذه التطبيقات بوجود هدف محدد قابل للقياس.
ما هو Unsupervised Learning؟
Unsupervised Learning هو أسلوب في تعلم الآلة يعتمد على تحليل بيانات غير مُعلَّمة لاكتشاف الأنماط أو التجمعات دون وجود نتائج مسبقة.
لا يحتوي هذا النوع على إجابات صحيحة معروفة، بل يركز على فهم البنية الداخلية للبيانات.
أبرز أنواعه:
– التجميع (Clustering).
– تقليل الأبعاد (Dimensionality Reduction).
– اكتشاف الارتباطات (Association).
الهدف هو استخراج معرفة جديدة من البيانات الخام.
كيف يعمل Unsupervised Learning؟
يعتمد على تحليل الخصائص المشتركة بين البيانات لتقسيمها إلى مجموعات متشابهة أو تحديد أنماط متكررة.
تمر العملية عادة بالمراحل التالية:
– إدخال بيانات غير مُعلَّمة.
– اختيار خوارزمية تحليل مناسبة.
– قياس التشابه أو المسافة بين العناصر.
– تكوين مجموعات أو تمثيلات جديدة.
– تفسير النتائج بناءً على السياق.
لا يتطلب هذا النهج إشرافًا بشريًا مباشرًا أثناء التدريب.
أمثلة على استخدامات Unsupervised Learning
يُستخدم عندما لا تكون النتائج معروفة مسبقًا أو عندما يكون الهدف استكشاف البيانات.
من التطبيقات الشائعة:
– تقسيم العملاء حسب السلوك الشرائي.
– اكتشاف الأنماط في البيانات البيولوجية.
– تحليل سلوك المستخدمين في المواقع.
– ضغط البيانات وتقليل أبعادها.
– أنظمة التوصية القائمة على التشابه.
يساعد هذا النهج في فهم البيانات قبل بناء نماذج تنبؤية.
ما الفرق الجوهري بين النهجين؟
الفرق الجوهري أن Supervised Learning يتعلم من بيانات تحتوي على إجابات صحيحة، بينما Unsupervised Learning يستكشف البيانات دون معرفة النتائج مسبقًا.
يمكن تلخيص الفروق الأساسية في النقاط التالية:
– نوع البيانات: مُعلَّمة مقابل غير مُعلَّمة.
– الهدف: التنبؤ بنتيجة محددة مقابل اكتشاف أنماط.
– التقييم: قياس دقة التوقع مقابل تحليل جودة التجميع.
– مستوى الإشراف: إشراف مباشر مقابل تحليل ذاتي.
– سهولة التطبيق: يتطلب الأول بيانات مُجهزة بدقة.
اختيار النهج يعتمد على طبيعة المشكلة والبيانات المتاحة.
متى يُفضل استخدام Supervised Learning؟
يُفضل استخدامه عند توفر بيانات تاريخية مُعلَّمة وعند الحاجة إلى تنبؤات دقيقة قابلة للقياس.
يكون مناسبًا في حالات:
– وجود هدف واضح محدد مسبقًا.
– توفر كمية كافية من البيانات المُعلَّمة.
– الحاجة إلى تقييم أداء النموذج بدقة.
– تطبيقات تتطلب قرارات آلية فورية.
يوفر نتائج قابلة للتحقق بسهولة عبر مؤشرات الأداء.
متى يُفضل استخدام Unsupervised Learning؟
يُفضل استخدامه عند غياب الوسوم أو عند الرغبة في استكشاف البيانات واكتشاف علاقات جديدة غير معروفة.
يكون مناسبًا في حالات:
– تحليل مجموعات كبيرة غير مُصنَّفة.
– البحث عن أنماط خفية.
– تقليل تعقيد البيانات.
– التحضير لنماذج تعلم مُراقب لاحقًا.
يُستخدم غالبًا كمرحلة تحليل أولي.
هل يمكن الجمع بين Supervised وUnsupervised Learning؟
نعم، يمكن الجمع بينهما في نماذج هجينة تستفيد من اكتشاف الأنماط أولًا ثم استخدامها في بناء نموذج تنبؤي أكثر دقة.
يُعرف ذلك أحيانًا بالتعلم شبه المُراقب، حيث تُستخدم كمية صغيرة من البيانات المُعلَّمة مع كمية أكبر غير مُعلَّمة.
يساعد هذا الأسلوب في تحسين الأداء وتقليل تكلفة إعداد البيانات.
ما التحديات المرتبطة بكل منهما؟
Supervised Learning يواجه تحدي جمع بيانات مُعلَّمة بدقة، بينما Unsupervised Learning يواجه صعوبة في تفسير النتائج وتقييم جودتها.
تشمل التحديات:
– تكلفة ووقت إعداد البيانات المُعلَّمة.
– احتمالية التحيز في الوسوم.
– صعوبة تحديد عدد المجموعات المثالي.
– تفسير الأنماط المكتشفة.
– خطر الإفراط في التعلّم.
فهم هذه التحديات يساعد في اختيار النهج الأنسب.

ما الفرق الأساسي بين التعلم المراقب وغير المراقب؟
التعلم المراقب يعتمد على بيانات مُعلَّمة للتنبؤ بنتائج معروفة، بينما التعلم غير المراقب يحلل بيانات غير مُعلَّمة لاكتشاف أنماط دون معرفة النتائج مسبقًا.
هل يحتاج التعلم غير المراقب إلى بيانات مُعلَّمة؟
لا، التعلم غير المراقب يعمل على بيانات بدون تسميات ويستخرج الأنماط تلقائيًا.
أيهما أدق في التنبؤ؟
التعلم المراقب أدق في التنبؤ عند توفر بيانات مُعلَّمة كافية وعالية الجودة.
هل يمكن استخدام النهجين في مشروع واحد؟
نعم، يمكن استخدام التعلم غير المراقب لاكتشاف الأنماط ثم بناء نموذج تعلم مُراقب اعتمادًا على النتائج.
ما أشهر خوارزميات التعلم المراقب؟
منها الانحدار الخطي، أشجار القرار، الشبكات العصبية، وآلة الدعم الناقل.
ما أشهر خوارزميات التعلم غير المراقب؟
منها K-Means، التجميع الهرمي، وخوارزميات تقليل الأبعاد مثل PCA.
هل التعلم غير المراقب أقل أهمية؟
لا، هو أساسي في استكشاف البيانات وفهمها ويُستخدم على نطاق واسع في التحليل والاكتشاف.







